In plain English
Apply AI finds you a job. You give it your CV and the kinds of roles you want, and it searches job sites across the web, ranks the ones that actually fit you, and even writes a first draft of your cover letter. Hours of searching become a few minutes.
AI job-search tool · Solo build
Apply AI
An AI tool that takes the grind out of job hunting. Upload your CV, choose the titles and roles you're after, and it scans 11 sources across the web (Jobindex, The Hub, LinkedIn, Greenhouse, Lever, HN "Who is hiring", +5 more), scores every result against your CV via Claude, drafts cover letters, and surfaces what to learn next from the roles you're closest to landing. Runs locally, so your CV never leaves your machine.
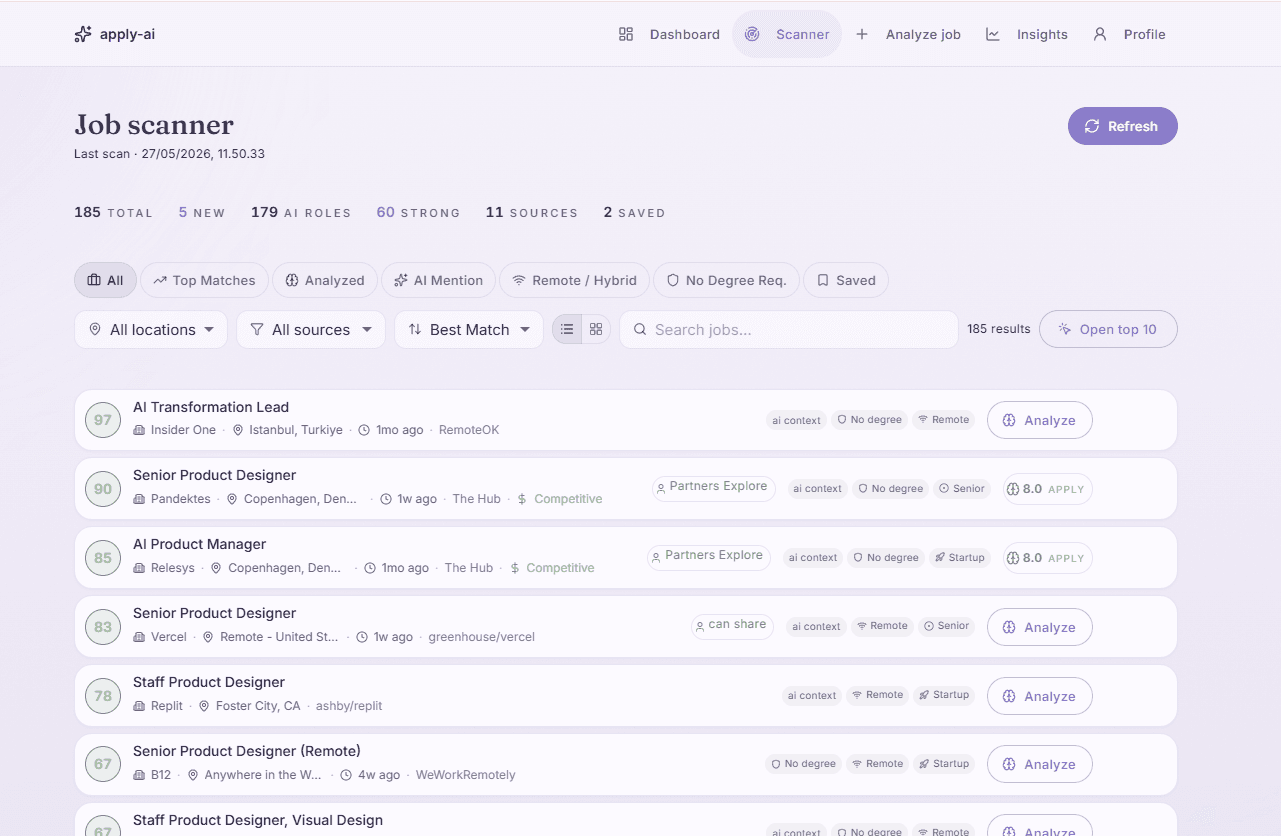
How it works
Upload your CV, pick your targets, let it scan
Drop in your CV, set the titles and roles you want plus filters like comp floor and dealbreakers, and Apply AI scans the web, scores each job against your CV, and drafts the cover letters. Everything runs locally, so your data stays yours.
By the numbers (latest scan)
Raw scraped
2,743
Across 11 sources in 30-45s
After dedup
993
URL canonicalisation, ~64% noise removed
Scored
185
Word-boundary keyword match + role tier weights
Stack cost
~$3/mo
Claude via OpenRouter, prompt caching on
Why I built this
Job hunting is mostly tedious filtering. The same roles get cross-posted across Jobindex, The Hub, LinkedIn and a dozen ATS platforms, half the "AI" jobs aren't actually AI-central, and reading every description to judge fit eats hours. I wanted to compress that loop.
So I built a tool that does it for you. Point it at your CV and the roles you want, and in about 30 seconds it pulls jobs from 11 sources, scores each one against your CV, and drops anything off-target like crypto or gambling. Claude then reads the strongest matches, writes a fit verdict and a cover-letter draft, and the dashboard shows you which skills keep coming up in the roles you should be landing.
Local-only by design: your CV and search data never leave your machine. And the build itself is the point, a small showcase of how I approach a messy problem: automate the tedious part, keep a human in the loop for the judgment calls.
How the pipeline works
Five stages from raw job feeds to a ranked list with cover letters drafted and skill-gap insights surfaced.
Scan 11 sources at once
Pulls jobs from 11 places at the same time (Jobindex, The Hub, LinkedIn, several ATS platforms, HN's "Who is hiring", and more). If one site is down, the rest still come through. A typical run gathers around 2,700 jobs in 30 to 45 seconds.
Remove the duplicates
The same role gets cross-posted everywhere, so it strips out the repeats and keeps one clean copy of each. On the last run that took about 2,700 raw listings down to under 1,000 real ones.
Score each job against your CV
Weights the roles you actually want more heavily, adds a bonus when a job is genuinely AI-focused, and drops anything in crypto, gambling, or defense to zero so it never wastes the budget on roles you'd skip anyway.
Claude reads and drafts
Claude reads the strongest matches against your CV, writes a fit verdict and a cover-letter draft, and skips anything it has already analysed. Caching keeps each one at roughly one to three cents.
Insights and apply tracking
A dashboard pulls it all together: the skills that keep coming up that you're missing, companies you keep meaning to apply to but never do, and a one-click way to mark what you've applied for.
Key features
11-source parallel scanner
Jobindex, The Hub, LinkedIn, IT Jobbank, Work in Denmark, AI Jobs, Remote OK, We Work Remotely, 5 ATS platforms, HN "Who is hiring". 30-45s wall time.
Hard-reject filter
Drops crypto / web3 / blockchain / gambling / weapons / surveillance jobs to 0 before they hit the analysis budget.
AI context bonus
Design or PM role + JD mentions ≥2 AI primary skills = +10. Lifts "Senior Product Designer at Lovable" above "Senior Product Designer at Maersk".
Claude with prompt caching
OpenRouter + Anthropic ephemeral cache on the system prompt. Content-hash skip on identical inputs. 3× retry with exponential backoff.
Cover letter drafts
Per-job cover letter using the 'strong' matched requirements only. Voice samples from your CV so the output sounds like you, not a template.
Insights + project recommender
45-skill ontology aggregates across all analyses. Surfaces weak skills with example roles, companies you keep analysing but never apply to, and Claude-generated weekend-sized projects to close the gaps.
Tech stack
Frontend
Material Design 3 dark theme (violet primary, MD3 surface tones), full migration from shadcn/ui to MUI v9 + Emotion. Tailwind kept for layout utilities.
Scanner
11 scrapers (RSS + HTML + JSON APIs). Direct ATS scraping for Greenhouse, Lever, Ashby, Teamtailor, Recruitee. Parallel via Promise.all with per-family try/catch.
AI
cache_control: ephemeral on the static system prompt. 3× retry with 1/3/7s backoff. Content-hash cache via sha256(jdText + profile) to skip identical re-analyses.
Storage
No database. Everything lives in data/*.json (profile, analyses, scanner jobs, seen URLs, scan status). One-user tool, file storage is enough.
Under the hood
Each job source is its own scraper and they all run in parallel, so one dead site never takes down a scan. Results get deduped, scored against your CV with layered rules, and only the strongest 30-50 are sent to Claude for the expensive part.
Claude calls reuse a cached prompt and skip anything already analysed, which keeps the whole thing running at a few dollars a month. Everything lives in plain local files, no database, because it's a one-person tool.
Brand & creative
Marketing posters and animated creative
Two brand posters and an animated 9:16 creative generated with Pomelli, Google's AI brand toolkit, to give the tool a real identity and test how far an AI brand kit can carry a product look from a single prompt.
 Brand poster
Brand poster Value prop
Value propCommon questions
Why does it run locally?+
So your CV and job data never touch a server, mine or anyone else's. The whole profile, analyses, scraped jobs and seen-URL memory live in local JSON files on your machine. It also keeps running costs near zero, since the only paid call is the Claude analysis.
How much does it actually cost to run?+
Roughly $3/month at my volume. Scraping is free. Claude analysis is the only paid call, and prompt caching plus the content-hash skip mean most analyses cost $0.01-$0.03 each. I run a full scan + analyse maybe 3-4 times a week.
Does the scoring actually work?+
Yes after the word-boundary fix. Before that, 'ai' matched 'available' and 'said' and 'email', so every Salesforce job scored well. The hardest single bug to find: a regex that was technically working but producing nonsense rankings. After the fix + tiered role weights + AI context bonus, the top 10 every morning are roles I'd actually apply to.
What's the AI doing that a smart regex couldn't?+
Two things. (1) Reading the prose of a JD to extract requirements that aren't bullet-listed (a lot of senior roles bury the actual ask in a paragraph). (2) Generating a per-job cover letter that mentions the matched requirements specifically. The hard scoring + filtering is regex; the per-job analysis and writing is Claude.
Open source?+
Not yet, but it's built to generalise. The CV and target roles are the personalisation layer, so nothing is hardcoded to one person. If there's interest, packaging it up as something others can run is the obvious next step.
What I learned
- ·A tiny detail can make or break the whole tool. One bad line in the scoring (matching "ai" inside "email") quietly ruined every ranking until I found it. With AI products, the boring plumbing matters more than the model.
- ·Caching the AI calls is basically free money. Reusing the same prompt and skipping anything already analysed cut the cost by about 70%, the difference between a tool I keep running and one I'd switch off.
- ·Keep a human in the loop where judgment matters. The tool ranks, filters, and drafts, but I still decide what to apply to. Automate the tedious 90%, leave the last 10% to a person, that's the pattern I keep coming back to.
What's next
Honest roadmap. Things I know are gaps, in priority order.
True CV upload + parsing
Right now the profile is structured by hand. Parsing an uploaded CV (PDF or LinkedIn export) straight into the profile + voice samples would make setup a 30-second job instead of a form.
Embeddings for skill matching
Skill ontology is 45 entries with manual alias lists. Embeddings (Voyage or OpenAI small) would catch the synonyms I forgot to add. Probably overkill at this corpus size, but the false-negatives bug me.
Hosted version with accounts
Today it's a local instance. A hosted version with per-user accounts and isolated storage would turn it from my workflow into something anyone could point at their own CV and targets.
Daily Telegram digest
Right now you open the dashboard. A daily push of 'today's 5 top-scored matches' would let you triage from your phone before the laptop opens.